The last 9 features are added from the Titanic passenger list on Wikipedia and are as follows: WikiId Name Age Hometown Boarded Destination Lifeboat Body Class
2. 요인별 생존 여부 관계
select * from mydata_titanic.full limit 10;
* 총인원 확인
select count(passengerid) n_passengers, count(distinct passengerid) n_d_passengers from mydata_titanic.full;
* 성별에 따른 승객수와 생존자 수
select sex, count(passengerid) as n_passengers, sum(survived) as n_survived
from mydata_titanic.full
group by 1;
* 성별 탑승객 수와 생존자 수의 비중
select sex, count(passengerid) as n_passengers, sum(survived) as n_survived,
sum(survived) / count(passengerid) as survived_ratio
from mydata_titanic.full
group by 1;
2-2. 연령, 성별
* 연령별 구간 나누기
select floor(age/10)*10 as ageband, age from mydata_titanic.full;
* 연령별 탑승객 수와 생존자 수, 생존율
select floor(age/10)*10 as ageband, count(PassengerId) as n_passengers,
sum(Survived) as n_passengers, sum(survived) / count(PassengerId) as survived_rate
from mydata_titanic.full
group by 1
order by 1;
* 성별 포함
select floor(age/10)*10 as ageband, sex, count(PassengerId) as n_passengers,
sum(Survived) as n_passengers, sum(survived) / count(PassengerId) as survived_rate
from mydata_titanic.full
group by 1,2
order by 1,2;
* 남성, 여성의 동일 연령대별 생존율 차이
select floor(age/10)*10 as ageband, sex, count(PassengerId) as n_passengers,
sum(Survived) as n_passengers, sum(survived) / count(PassengerId) as survived_rate
from mydata_titanic.full
group by 1,2
having sex='male'
order by 1;
select floor(age/10)*10 as ageband, sex, count(PassengerId) as n_passengers,
sum(Survived) as n_passengers, sum(survived) / count(PassengerId) as survived_rate
from mydata_titanic.full
group by 1,2
having sex='female'
order by 1;
2개 테이블을 서브쿼리로 생성, 조인
b.survived_rate - a.survived_rate as survived_rate_diff
from (select floor(age/10)*10 as ageband, sex,
count(passengerid) as n_passengers,
sum(survived) / count(passengerid) as survived_rate
from mydata_titanic.full
group by 1,2
having sex='male') as a
left join (select floor(age/10)*10 as ageband, sex,
count(passengerid) as n_passengers,
sum(survived) as n_survived,
sum(survived) / count(passengerid) as survived_rate
from mydata_titanic.full
group by 1,2
having sex='female' ) as b
on a.ageband=b.ageband
order by a.ageband;
2-3. Pclass (객실등급)
select distinct pclass from mydata_titanic.full;
* 객실 등급별로 승객 수와 생존자 수, 생존율
select pclass, count(passengerid) as n_passengers,
sum(survived) as n_survived,
sum(survived) / count(passengerid) as survived_rate
from mydata_titanic.full
group by pclass
order by 1;
* 객식 등급, 연령, 성별, 생존율
select pclass, sex, count(passengerid) as n_passengers,
sum(survived) as n_survived,
sum(survived) / count(passengerid) as survived_rate
from mydata_titanic.full
group by pclass, sex
order by 2, 1;
select pclass, sex, floor(age/10)*10 as ageband,
count(passengerid) as n_passengers,
sum(survived) as n_survived,
sum(survived) / count(passengerid) as survived_rate
from mydata_titanic.full
group by pclass, sex, floor(age/10)*10
order by 2, 1;
3. Embarked
* 승선 항구별 승객 수
select embarked, count(passengerid) as n_passengers
from mydata_titanic.full
group by 1
order by 1;
* 승선 항구별, 성별 승객 수
select embarked,sex, count(passengerid) as n_passengers
from mydata_titanic.full
group by 1,2
order by 1,2;
* 승선 항구별, 성별 승객 비중(%)
승선 항구별, 성별 승객수
select embarked, sex, count(passengerid) as n_passengers
from mydata_titanic.full
group by 1,2
order by 1;
4. 탑승객 분석
* 출발지, 도착지별 승객 수
select boarded, destination, count(passengerid) as n_passengers
from mydata_titanic.full
group by Boarded, Destination
order by 3 desc;
타이타닉 경로 : 영국 Southampton > 미국 New York
영국 Southampton > 미국 New York 의 승객수가 가장 많았고
그 다음으로는 Cherbourg > New York
* 상위 5개 경로 선택한 승객들의 이름 추출
select *, row_number() over(order by n_passengers desc) as RNK
from (select boarded, destination, count(passengerid) as n_passengers
from mydata_titanic.full
group by boarded, destination) base;
테이블 생성
create temporary table mydata_titanic.route as
select boarded, destination from
(select *, row_number() over(order by n_passengers desc) as RNK
from (select boarded, destination, count(passengerid) as n_passengers
from mydata_titanic.full
group by boarded, destination) base) base
where RNK between 1 and 5;
select name_wiki, a.boarded, a.destination from mydata_titanic.full a
inner join mydata_titanic.route b
on a.boarded=b.boarded and a.destination = b.destination;
* 홈타운별 탑승객 수 및 생존율
select hometown, sum(1) as n_passengers, sum(survived) / sum(1) as survived_ratio
from mydata_titanic.full
group by 1;
* 팁승객 수 10명 이상, 생존율 0.5 이상
select hometown, sum(1) as n_passengers, sum(survived)/sum(1) as survived_ratio
from mydata_titanic.full
group by 1
having sum(survived)/sum(1) >= 0.5 and sum(1) >=10;
5. 상관분석(Correlation Analysis)
* R프로그램에서 SQL로 데이터 불러오기
# MySQL과 R을 연동해 주는 패키지 설치
install.packages('RMySql') #1
# 패키지 실행
library(RMySql) #2 (MySql 접속 패키지)
library(dplyr) # 데이터 전처리 패키지
# 접속 정보 입력
mydb=dbConnect(MySql(),
user='id', # MySQL 접속계정
password = 'password', # MySQL 접속계정 패스워드
dbname ='mydata', # 데이터베이스명
host='localhost') # DB IP (local에 접속하는 경우 : localhost) #3
# 데이터 data
data=dbGetQuery(mydb,'select * from mydata.dataset4') #4
# 문자열 숫자로 변경
data$Sex=ifelse(data$Sex =='female',1,0)
# 분석할 변수 가져오기
M=data %>% select(Survived, Age, Sibsp, Parch, Fare, Sex)
# 상관계수 구하기
install.packages('corrplot') # 상관계수 분석 패키지 설치
library(corrplot) # 상관계수 패키지 불러오기
corr=cor(M) # 상관계수 계산하기
corrplot(corr,method='circle") # 상관계수 시각화
업무별 데이터 분석 절차
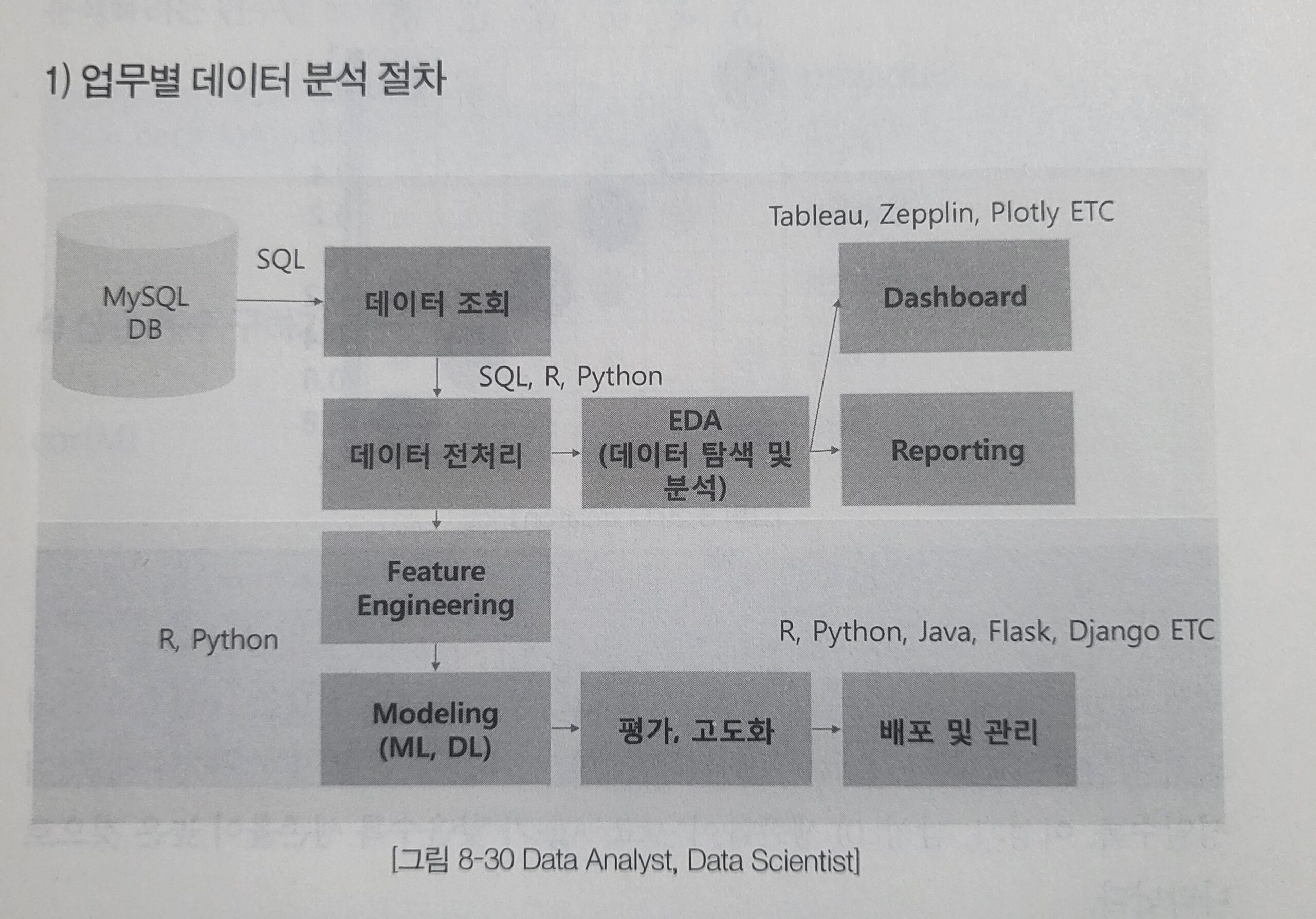
데이터 분석 절차 SQL Python Tableau
1장 데이터베이스와 SQL
2장 SQL문법
3장 데이터 추가, 삭제, 갱신, 데이터 정합성
4장 자동차 매출 데이터를 이용한 리포트 작성
5장 상품 리뷰 데이터를 이용한 리포트 작성
6장 식품 배송 데이터 분석
7장 UK Commerce 데이터를 이용한 리포트 작성
8장 타이타닉 호 데이터 분석
9장 R, Python 연동